⚙️ Automatic snapshot creation in CI for Playwright
It can be tedious to update baseline images as a part of your visual regression suite, so I've created a pipeline to automatically generate them and open a pull request for you
Introduction
Visual regression with Playwright is generally very simple, and you can create suites of tests quickly with it. The only aspect that I've found quite tedious, is the updating of baseline images when the website has changed.
The updating of images is just a one line command npx playwright test --update-snapshots, but the complexity comes with where your tests are executed.
If we run that command on my local machine and then try to execute the tests on a CI pipeline, they will almost certainly fail as the test execution environment is different.
Solution?
The first solution is to use Docker containers, and this is generally how everyone approaches it. You run a CI pipeline that uses an image mcr.microsoft.com/playwright:v1.49.0-noble for example, and your visual snapshots will always be the same dimensions.
Next you add a step in the CI pipeline to create a zip file with your new baseline images, pull them to local, create a branch and a new PR and push your new baseline images to master/main.
That's the part I don't like - too much human intervention.
So let's automate it.
Setup
In order to track snapshot versions, I'm using a value in the .env file like this:
SNAPSHOT_VERSION=1
This is the spec file I am using and you can see where the snapshot version is being referenced. I've added 3 url's which I want to run visual regression for, and the folder structure will reflect this.
import { test, expect } from '@playwright/test';
import dotenv from 'dotenv';
import fs from 'fs';
// Load environment variables from .env
dotenv.config();
test.describe('Snapshot tests with versioned folders', () => {
const urls = [
{ name: 'docker', url: 'https://docker.com' },
{ name: 'playwright', url: 'https://playwright.dev' },
{ name: 'google', url: 'https://google.com' },
];
const snapshotVersion = process.env.SNAPSHOT_VERSION;
if (!snapshotVersion) {
throw new Error('SNAPSHOT_VERSION is not defined in the .env file.');
}
urls.forEach(({ name, url }) => {
test(`snapshot test for ${name}`, async ({ page }) => {
await page.goto(url);
// Define the relative path inside the test's snapshot directory
const screenshotPath = [`${name}`, `version-${snapshotVersion}`, 'base.png'];
// Save the screenshot to the nested path
await expect(page).toHaveScreenshot(screenshotPath);
});
});
});
Next is the important part where all of the magic happens. This is the YML pipeline, I'll step through what we are doing, but it's also outlined in the file comments.
- Reference Playwright image to run tests in container
- Checkout/pull main branch
- Increment the snapshot version in our .env file
- Setup Node and run Playwright test + update snapshot command
- Create a pull request
The nice thing about this pre-defined Action uses: peter-evans/create-pull-request@v7, is that it tracks the changes made, checks if a branch exists and if not, creates one for us.
name: Playwright Baseline Update
on:
workflow_dispatch: # Allows manual triggers
push:
branches: [main, master]
pull_request:
branches: [main, master]
jobs:
playwright:
name: 'Playwright Tests and Baseline Update'
runs-on: ubuntu-latest
container:
image: mcr.microsoft.com/playwright:v1.49.0-noble
options: --user 1001
steps:
# Step 1: Checkout the repository and pull the latest main
- name: Checkout and Pull Main
uses: actions/checkout@v4
with:
ref: main
- name: Ensure Latest Main
run: |
git fetch origin main
git checkout main
git pull origin main
# Step 2: Ensure .env file exists and increment the snapshot version
- name: Manage Snapshot Version
run: |
# Ensure .env exists with default version
if [ ! -f .env ]; then
echo "SNAPSHOT_VERSION=1" > .env
fi
# Read the current version and increment it
CURRENT_VERSION=$(grep SNAPSHOT_VERSION .env | cut -d '=' -f2)
NEW_VERSION=$((CURRENT_VERSION + 1))
sed -i "s/SNAPSHOT_VERSION=$CURRENT_VERSION/SNAPSHOT_VERSION=$NEW_VERSION/" .env
# Commit the updated .env file
git config --global user.name "${{ secrets.GIT_USERNAME }}"
git config --global user.email "${{ secrets.GIT_EMAIL }}"
git add .env
git commit -m "Increment snapshot version to $NEW_VERSION"
# Step 3: Set up Node.js and install dependencies
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: lts/*
- name: Install Dependencies
run: npm ci
# Step 4: Run Playwright tests and update snapshots
- name: Run Playwright Tests
run: npx playwright test --update-snapshots
# Step 5: Create a pull request for the updated baselines
- name: Create Pull Request
uses: peter-evans/create-pull-request@v7
with:
token: ${{ secrets.GITHUB_TOKEN }}
branch: pr-update-visual-baselines-${{ github.run_id }}
base: main
title: "Update visual regression baseline"
body: |
This pull request updates the visual regression baseline snapshots after running Playwright tests.Let's run the CI
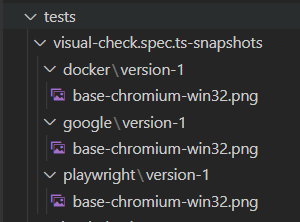
So this is what our local looks like, we have our folders and the version is 1.
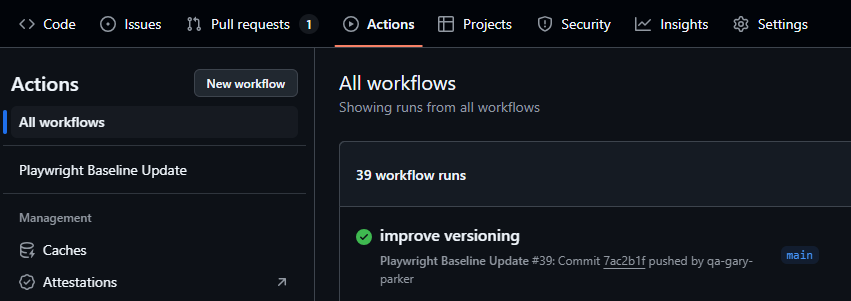
I'm going to run the pipeline and you can see once its completed a pull request has been made:
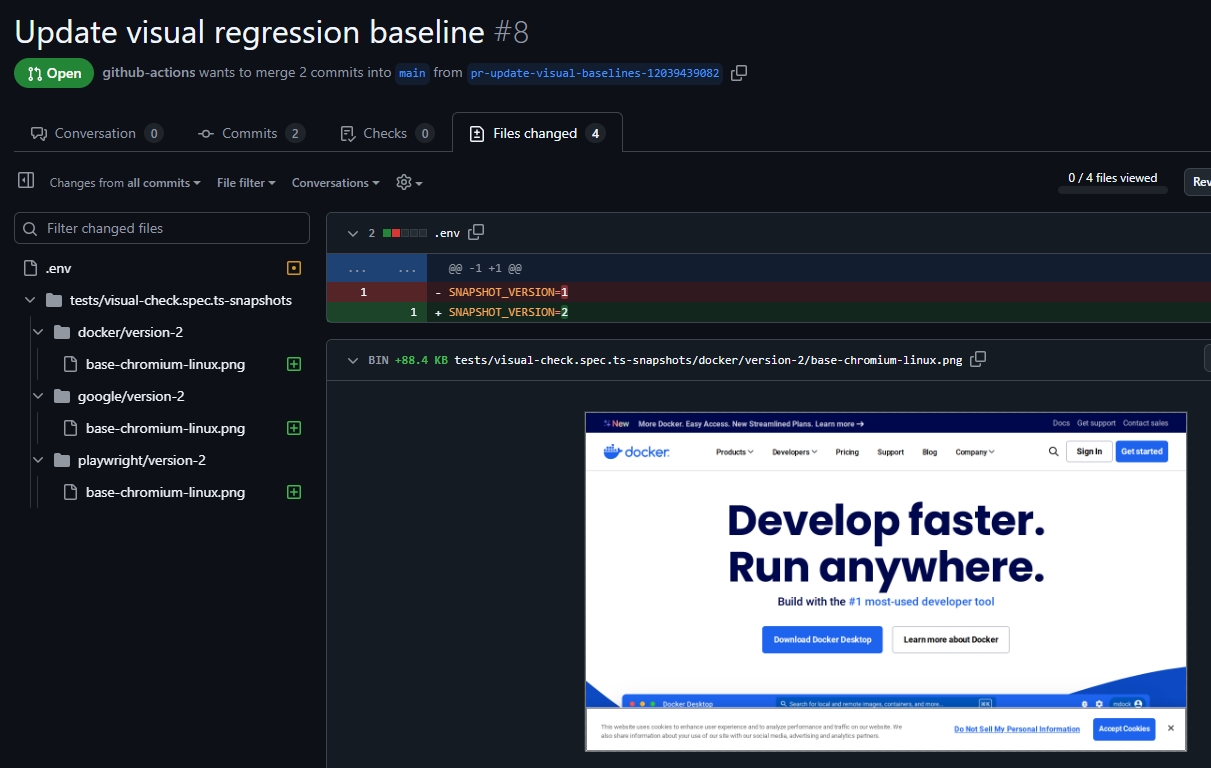
If we go in and check what the changes are, you can see there are 4 in total. The .env increment, and our 3 new baseline images.
Once this is merged, everything will still work perfectly because the version number is defined in our test:
const screenshotPath = [`${name}`, `version-${snapshotVersion}`, 'base.png'];
The number will now reference version 2, and we will maintain a history of previous image versions if needed.
Conclusion
Let me know what you think - it seems like a nice process to update a large suite of baseline images in one go, without the hassle of manually managing image files.